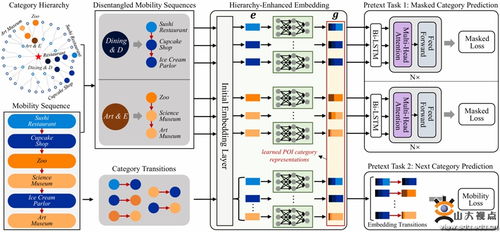
微软出手立规矩 AI公司不能白拿数据,人工智能基础软件开发迎来新范式
在人工智能浪潮席卷全球的当下,数据的价值被提升到了前所未有的战略高度。数据获取与使用的边界、伦理与规则,长期以来一直是行业发展的灰色地带。科技巨头微软率先“出手”,明确提出并为行业“立规矩”——人工智能公司不能无偿、无限制地使用数据,特别是用于训练基础模型。这一举措,不仅是对现有商业模式的挑战,更是对人工智能基础软件开发范式的一次深刻重塑。
一、 规则的核心:为数据价值正名,确立使用边界
微软所倡导的规则,核心在于承认并保护数据创造者的权益。过去,许多AI公司在开发大型语言模型、计算机视觉模型等基础软件时,普遍采取从公开互联网海量抓取数据的方式进行训练。这种行为虽在技术上高效,但在法律和伦理层面日益引发争议,涉及版权、隐私和公平竞争等多重问题。
微软的立场清晰地表明:数据并非“免费的午餐”。无论是个人用户生成的内容、专业机构生产的版权材料,还是企业运营中积累的专有信息,其价值都应得到尊重和补偿。这意味着,AI公司在开发基础模型时,必须建立更透明、更合规的数据获取与使用机制,可能包括:
- 获得明确授权:对于受版权保护或包含个人隐私的数据,需事先获得权利人的许可。
- 建立公平补偿机制:探索数据许可费、收益分成等模式,使数据提供者能从AI创造的价值中获益。
- 确保数据使用的透明度:向用户和监管机构披露关键数据来源及使用方式。
二、 对AI基础软件开发的影响:成本、质量与创新的再平衡
这一规则的树立,将对人工智能基础软件的开发流程产生深远影响。
- 开发成本结构变化:数据从“零成本原材料”变为需要预算的“生产要素”,短期内可能推高模型训练的直接成本。这将促使公司更精细地评估数据价值,追求更高数据效率的训练方法。
- 数据质量与合规性成为核心竞争力:依靠合法授权、高质量、多样化的数据集训练的模型,将更具商业安全性和伦理优势。这有助于淘汰那些纯粹依靠“数据搬运”的粗放模式,推动行业向更健康、更可持续的方向发展。
- 催生新的数据生态与合作模式:规则将鼓励数据市场、数据联盟、授权平台等新型业态的发展。AI公司可能与内容出版商、研究机构、特定行业企业建立深度数据合作,开发更具领域针对性、更可靠的基础模型。
- 推动技术创新方向:在数据获取受限或成本增加的背景下,学术界和工业界将更加关注如何用更少的数据训练出性能相当的模型(如小样本学习、高效微调)、如何生成高质量的合成数据,以及如何通过算法改进来降低对海量瑕疵数据的依赖。
三、 微软的标杆作用与行业未来
作为在AI领域投入巨资(如与OpenAI的深度合作)并同时提供广泛云服务与企业解决方案的巨头,微软此举具有强烈的标杆意义。它不仅是自身合规风险的主动管理,也意在塑造一个对其既有业务(如Azure AI、拥有大量版权内容的专业云服务)更有利的行业环境。
可以预见,这一“规矩”将产生连锁反应:
- 立法与监管加速:微软等行业领袖的自我规范,将为全球各国正在制定中的AI数据监管政策提供重要参考,加速相关立法的进程。
- 行业标准逐步形成:其他大型科技公司和有责任的AI初创企业可能会跟进或提出类似准则,共同推动形成行业通行的数据伦理与使用标准。
- 竞争格局演变:拥有合法数据资源、能建立良性数据生态的企业将获得长期优势。纯粹依赖爬取数据的商业模式将面临巨大挑战,必须转型。
- 激发数据创造者积极性:当创作者和机构看到其数据能获得合理回报,可能会更积极地参与高质量数据的生产和分享,从而丰富AI训练的“养分”,最终促进更强大、更负责任的AI发展。
###
微软“立规矩”,标志着人工智能行业从野蛮生长的“拓荒时代”,开始迈向讲究规则、注重权益平衡的“精耕时代”。它明确了“AI公司不能白拿数据”这一基本原则,为人工智能基础软件的开发划下了一条清晰的起跑线。这条规则虽然短期内可能带来阵痛,但长远看,它通过确立数据价值的公平交换,旨在构建一个更健康、更可信、更可持续的AI创新生态。未来AI的竞争,将不仅仅是算法和算力的竞争,更是数据伦理、合规生态和合作模式的竞争。
如若转载,请注明出处:http://www.1024planet.com/product/51.html
更新时间:2026-02-28 15:35:41